In Part 1 of the series CI/CD on Kubernetes we used the PodNodeSelector admission controller to segregate the Jenkins workloads - agents from masters (and from any other workload running on the cluster). In Part 2 of this CI/CD on Kubernetes series we will utilize the segregated jenkins-agents node pool as part of an autoscaling solution for the Jenkins agent workload, without impacting the availability or performance of the Jenkins masters node pool or any other segregated workload on the cluster. But before diving into an autoscaling solution for Jenkins agents we will take a look at two ways to manage compute resources for containers with Kubernetes: ResourceQuotas and LimitRanges. Managing compute resources for the cluster will reduce the risk of a few rogue Jenkins jobs effecting the stability and availability of agent capacity, and ensure more predictable autoscaling. Because even though autoscaling compute resources for Jenkins agents is a terrific solution for flexibile and dynamic CI/CD capacity, there will always be a limits to how much up-scaling is possible - whether it is limits on cost or actual physical limitations of AWS itself.
NOTE: The configuration examples used in this series are from a Kubernetes cluster deployed in AWS using Kubernetes Operations or kops version 1.9 with Kubernetes RBAC enabled (which is the default authorization mode for kops 1.9). Therefore, certains steps and aspects of the configurations presented may be different for other Kuberenetes platforms.
Resource Quotas and Autoscaling Don’t Mix
Resource Quotas
Efficient and effective management of compute resources is an important part of successful CI/CD and it is no different with CI/CD on a Kubernetes cluster. The Kubernetes ResourceQuota object allows you to limit cluster resource utilization by namespace - ensuring that each workload or team that has a dedicated namespace has adequate compute resources without denying resources to other workloads/teams. ResourceQuotas, for example, allow you to specify the total compute resources, such as cpu and memory (among many other types of Kubernetes resources), that may be used by a namespace - think of them as over-utilization guardrails for your CI/CD resources. However, it is a static configuration and more useful when sharing a node pool across multiple namespaces. So, with ResourceQuotas, if you were to increase the number of nodes in a cluster you would have to manually update the ResourceQuota to make additional resources available for any namespace with a ResourceQuota. However, the topic of this post is how to dynamically up-scale and down-scale cluster nodes for Jenkins agents - but it is not currently possible to dynamically modify ResourceQuotas. So, there doesn’t seem much point in having cluster autoscaling while requiring a manual process to modify ResourceQuotas in order to actually utilize the autoscaled resources - so ResourceQuotas and autoscaling by namespace don’t mix.
Limit Ranges
Even though ResourceQuotas don’t make much sense with node pool autoscaling (especially when segregating node pools by namespace), you still will want to provide some guardrails within a segregated namespace so that one individual Jenkins job does not adversely effect other jobs relying on the same pool of Jenkins agent capacity. First and foremost, we want to ensure that no single pod is configured to use more resources than are available on a single node as that pod will fail to launch - resulting in the Jenkins jobs requesting those agents waiting indefinitely in the Jenkins job queue. Additionally, for a Kubernetes cluster configured to autoscale nodes we still will want to have reasonable limits for each individual Jenkins agent pod as we will certainly have a max-limit for how many nodes can be up-scaled - and we wouldn’t want some rogue Jenkins jobs monopolizing most, if not all, of the compute resources of the Jenkins agent node pool. So we will define a LimitRange for the jenkins-agent namespace to assure realistic defaults and limits for each container in a pod and maximum cpu and memory limits for each pod. This will provide for more consistent and reasonable resource utilization and more predictable cluster autoscaling.
NOTE: Using
LimitRangerequires that theLimitRangeradmission controller be enabled. TheLimitRangeradmission controller has been a recommended admission controller since Kubernetes 1.0 and will most likely be enabled by default for most Kubernetes distributions. It is enabled by default for kops 1.9.
apiVersion: v1
kind: LimitRange
metadata:
name: jenkins-agent-limit-range
namespace: jenkins-agents
spec:
limits:
- type: Pod
max:
cpu: 3
memory: 8Gi
- type: Container
max:
cpu: 2
memory: 4Gi
min:
cpu: 0.25
memory: 500Mi
NOTE: Even though we won’t be using
ResourceQuotasfor this example - it is interesting thatResourceQuotasandLimitRangeswork hand-in-hand. If aResourceQuotais specified for cpu and/or memory on anamespacethenpodcontainersmust specify limits or requests for cpu/memory or thepodmay not be created. So it is recommended that aLimitRangeis created for anynamespacethat has aResourceQuotaapplied - so default values are automatically applied to anycontainersthat don’t specify cpu/memory limits or requests resulting in a successfully scheduledpod.
Why Autoscale Agents
The Jenkins Kubernetes Plugin provides the capability to provision dynamic and ephemeral Jenkins agents as Pods managed by Kubernetes. And while very useful, that is not the same thing as autoscaling the actual physical resources or nodes where these Pods are running. Without true autoscaling, there will be a static amount of resources available for your Jenkins agents workload (and any other applications utilizing those same Kubernetes nodes); and when and if all of those resources are consumed - any additional Jenkins workload will be queued. Autoscaling the Jenkins agent capacity will help minimize queuing for expected or random spikes in a CI/CD workload - especially in a cloud environment like AWS, Azure, GCP, etc.
True autoscaling will allow your CI/CD to move as fast as it needs to - greatly reducing slow-downs related to lack of infrastructure. But of course you will still want to set maximum limits to avoid large costs due to a mis-configured jobs or other user error - even with a LimitRange for the autoscaled namespace. And remember, down-scaling is just as important as up-scaling - it is the down-scaling that will help manage costs by removing under utilized nodes, while the up-scaling accelerates your CI/CD. Autoscaling will help manage costs and while maximizing the availability of Jenkins agents.
Kubernetes Autoscaler Project
The Kubernetes Autoscaler project provides a Cluster Autoscaler component with support for AWS, GCP and Azure. A GA version was released alongside the release of Kubernetes 1.8. The Cluster Autoscaler runs as a Kubernetes Deployment on your cluster and monitors the resource utilization of node pools or in kops terms InstanceGroups - which for AWS map to AutoScalingGroups. The Cluster Autoscaler will up-scale and down-scales nodes in a node pool/instancegroup based on pod consumption. Configuring and enabling the Kubernetes Cluster Autoscaler is very simple and straightforward as we will see below.
NOTE: There are two other prominent types of autoscaling for Kubernetes: 1) The Horizontal Pod Autoscaler and 2) The Vertical Pod Autoscaler. Put simply, the Horizontal Pod Autoscaler scales the number of
Podsfor a given application and is not a good fit for stateful, singlepodapplications like Jenkins masters or the ephemeral workload of Kubernetes based Jenkins agents. The Vertical Pod Autoscaler is of potential interest for both Jenkins masters and agents - as it will automatically adjust resource requirements for new and existing pods. One area of interest for the Vertical Pod Autoscaler is the capability to reduce the risk of containers running out of memory. This could be an excellent feature for Jenkins masters, allowing you to be more frugal with initial resource quotas with less risk. Definitely something worth taking a look at in a future post.
Namespace Specific Autoscaling
We want to run a number of different workloads on our Kubernetes cluster - for example, in addition to providing dynamic Jenkins agents, we would also like to run Jenkins masters on the cluster and even deploy production applications to the same cluster. Of course you could set up separate clusters for each of these workloads, but the Kubernetes Namespace capability provides manageable multi-tenant workloads, all within one Kubernetes cluster. For some workloads autoscaling is quite useful, whereas for other types of workloads autoscaling may not make sense, and may even be detrimental. Specifically, cluster autoscaling is not a good fit for Jenkins masters. The Cluster Autoscaler will down-scale in addition to up-scaling - and when it scales down it will move/reschedule existing pods to other nodes in the pool so that node can be removed from the node pool. These sudden unexpected stoppages for down-scaling is not a behavior we want for the Jenkins masters’ workloads. But cluster autoscaling makes a lot of sense for Jenkins agents. So we will use the Jenkins agent namespace tied to a Jenkins agent node pool created in part one of this series to ensure that only nodes used by Jenkins agents - and not other workloads - are autoscaled.
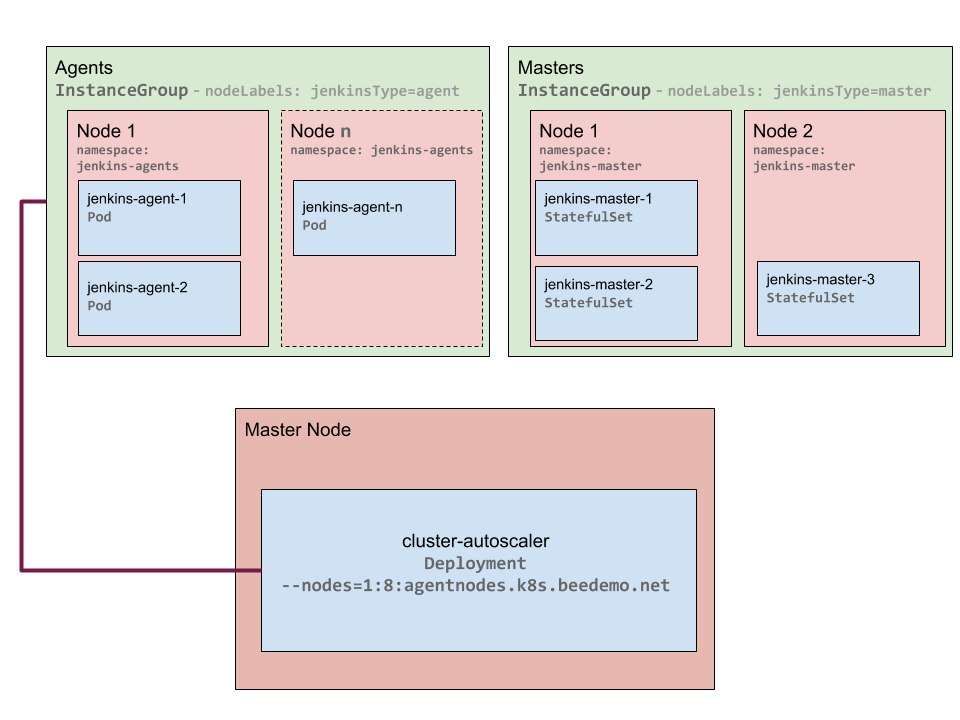
Kubernetes Autoscaling Architecture Overview Diagram
PodNodeSelector
The PodNodeSelector admission controller that we setup in part one of this series allows for targeted cluster autoscaling. To revisit, the PodNodeSelector allows you to place an annotation on a Kubernetes namespace that will automatically be assigned as a nodeSelctor label/value on all pods that are created in that namespace. We will configure the Cluster Autoscaler to specifically target the AWS AutoScalingGroup backed node pool/InstanceGroup associated to the Jenkins agent namespace created in part one of this series using the PodNodeSelector, resulting in only nodes used for Jenkins agent pods being autoscaled.
Cluster Autoscaler Deployment
The following is an excerpt from the cluster autoscaler example for running on a master node with the only modifications being for the nodes argument for the cluster-autoscaler app, the version of the cluster-autoscaler image used which maps to specific Kubernetes versions as documented here and in this case is v1.1.0 for Kubernetes version 1.9.3 and the AWS_REGION envrionment variable:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
k8s-addon: cluster-autoscaler.addons.k8s.io
app: cluster-autoscaler
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
nodeSelector:
kubernetes.io/role: master
serviceAccountName: cluster-autoscaler
containers:
- name: cluster-autoscaler
image: k8s.gcr.io/cluster-autoscaler:v1.1.0
.
.
.
command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false
- --nodes=2:10:agentnodes.k8s.kurtmadel.com
env:
- name: AWS_REGION
value: us-east-1
.
.
.
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2018-05-25T11:30:23Z
labels:
kops.k8s.io/cluster: k8s.kurtmadel.com
name: agentnodes
spec:
image: kope.io/k8s-1.8-debian-stretch-amd64-hvm-ebs-2018-02-08
machineType: m5.xlarge
maxSize: 1
minSize: 10
nodeLabels:
jenkinsType: agents
kops.k8s.io/instancegroup: jenkins-agents
role: Node
subnets:
- us-east-1b
NOTE: The Cluster Autoscaler also supports an auto-discovery mode that allows you to tag a
node poolwith two keys -k8s.io/cluster-autoscaler/enabled=yesandkubernetes.io/cluster/<YOUR CLUSTER NAME>=true- and the Cluster Autoscaler will automaticlaly discover and scale thosenode pools. However, with the Jenkins agent use case presented here we are targeting a specific kopsInstanceGroups/node poolsfor a specific workload that we want autoscaled while we have othernode poolswhere we explicitly don’t want autoscaling. So we will stick with the deliberate configuration shared above.
One thing to keep in mind when autoscaling Jenkins agent workloads, specifically with a cloud provider like AWS, is that spinning up a new node/EC2 instance takes ~4 minutes on average - time jobs will be waiting in the Jenkins queue (in addition to the ~10 seconds it takes the Cluster Autoscaler to decide to scale-up). In the next post of the series CI/CD on Kubernetes we will explore just-in-time autoscaling for the Jenkins agent workload that I like to refer to as preemptive autoscaling. This will allow us to further minimize Jenkins job queueing due to unavailable agent capcity by scaling-up the Jenkins agent node pool just before we need additional capacity.